Simulate Linear Regression with Torch
Posted on June 2, 2019
Tags: machinelearning
1 Imports
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltBoston = pd.read_csv("../dataset/Boston.csv")x = Boston['lstat']
y = Boston['medv']import torch
print("Using torch", torch.__version__)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")Using torch 1.11.0X = torch.FloatTensor(x)
Y = torch.FloatTensor(y)
print(X.shape,Y.shape) torch.Size([506]) torch.Size([506])2 Creating your Dataset class
import torch.utils.data as dataclass myDataset(data.Dataset):
def __init__(self):
super().__init__()
self.generateData()
def generateData(self):
self.data = X
self.label = Y
self.size = len(Y)
def __len__(self):
# Number of data point we have. Alternatively self.data.shape[0], or self.label.shape[0]
return self.size
def __getitem__(self, idx):
# Return the idx-th data point of the dataset
# If we have multiple things to return (data point and label), we can return them as tuple
data_point = self.data[idx]
data_label = self.label[idx]
return data_point, data_labelMainDataset = myDataset()len(MainDataset) 506MainDataset[3](tensor(2.9400), tensor(33.4000))3 Building the Neuron
import torch.nn as nn
import torch.nn.functional as Fclass ExampleNeuron(nn.Module):
def __init__(self, num_inputs, num_hidden, num_outputs):
super().__init__()
self.linear1 = nn.Linear(num_inputs, num_hidden)
# self.act_fn = nn.Tanh()
self.linear2 = nn.Linear(num_hidden, num_outputs)
def forward(self,x):
x = self.linear1(x)
# x = self.act_fn(x)
x = self.linear2(x)
return xmodel = ExampleNeuron(num_inputs=1, num_hidden=2, num_outputs=1)4 Loss function
loss_module = nn.MSELoss()5 Gradient Descent
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4,weight_decay=1e-6)6 Training - Putting it all together
train_dataset = MainDataset
train_data_loader = data.DataLoader(train_dataset, shuffle=True)def train_model(model, optimizer, data_loader, loss_module, num_epochs=100):
# Set model to train mode
model.train()
# Training loop
for epoch in range(num_epochs):
for data_inputs, data_labels in data_loader:
## Step 1: Move input data to device (only strictly necessary if we use GPU)
data_inputs = data_inputs.to(device)
data_labels = data_labels.to(device)
## Step 2: Run the model on the input data
preds = model(data_inputs.float())
## Step 3: Calculate the loss
loss = loss_module(preds, data_labels)
## Step 4: Perform backpropagation
# Before calculating the gradients, we need to ensure that they are all zero.
# The gradients would not be overwritten, but actually added to the existing ones.
optimizer.zero_grad()
# Perform backpropagation
loss.backward()
## Step 5: Update the parameters
optimizer.step()train_model(model, optimizer, train_data_loader, loss_module)- The function call
train_modelmutates AKA trains themodelobject.
7 Prediction of single example
- To make a prediction simply pass a input tensor value into
model(..)model(torch.FloatTensor([14.1]))
print("original datapoint: ",MainDataset[150],"\n")
singleinput = torch.FloatTensor([14.1])
singleprediction = model(singleinput) #Really this simple to make a prediction
print(f" input:{singleinput}\n prediction:{singleprediction}") original datapoint: (tensor(14.1000), tensor(21.5000))
input:tensor([14.1000])
prediction:tensor([16.9899], grad_fn=<AddBackward0>)Input with 14.1, has a real value of 21.5 while our prediction is 16.9899
8 Plotting list of predictions
BE VERY CAREFUL: train_data_loader is shuffled shuffle=True
Referring to codeblock below:
data_inputsis an randomly ordered.- A BAD naive append would be to create only a list of predictions(VERSUS a tuple that pairs prediction with input).
- If you plot our original ordered inputs with the naive append unordered predictions, you made a mistake
- Alternative solution would be to make another data_loader that with
shuffled=Falseand loop over thatvisualize_data_loader = data.DataLoader(train_dataset, shuffle=False)
acc = [] #list of tuples [(x5,pred_y5),(x2,pred_y2),(x7,pred_y7)..]
for data_inputs, data_labels in train_data_loader: #REMEMBER it is shuffed AKA unordered
unordered_pred = model(data_inputs.float()).detach().numpy()
unordered_input = data_inputs.detach().numpy()
acc = acc + [(unordered_input,unordered_pred)] #Important to ppair BOTH unordered input and unordered output
#acc = acc + [unordered_pred] #BAD naive append
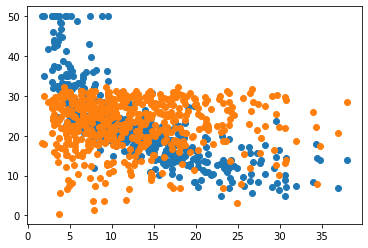
unorderedX,unorderedY = zip(*acc) #zip(*acc) is the unzip operation; extracts [(x1,y1),(x2,y2),...] => [x1,x2..] [y1,y2..]plt.scatter(X,Y)
plt.scatter(unorderedX,unorderedY) 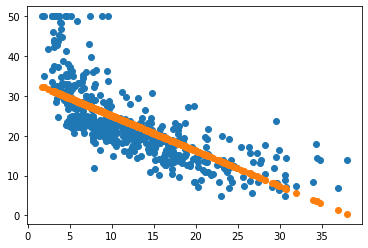
BAD
plt.scatter(X,Y) #These X and Y are ordered
plt.scatter(X,unorderedY) #Very BAD